This page is a translated version of an original text written by me. It was translated with the assistance of AI.
Claude Deep Research, or How I Learned to Stop Worrying and Love Multi-Agent Systems
A look at the current state of multi-agent systems through the lens of a recent article from Anthropic. An analysis of the Deep Research architecture, its strengths, weaknesses, and practical takeaways for anyone building complex AI systems in the real world.
I usually approach shiny new things with a healthy dose of skepticism. Until recently, this was precisely my attitude toward multi-agent systems. This is hardly surprising, given the immense hype surrounding them and the conspicuous absence of genuinely successful examples. Most implementations that actually worked fell into one of the following categories:
Agentic systems following a predefined plan. These are essentially LLMs with tools, trained to automate a very specific process. This approach allows each step to be tested individually and its results verified. Such systems are typically described as a directed acyclic graph (DAG), sometimes dynamic, and developed using now-standard primitives from frameworks like LangChain and Griptape1. The early implementation of Gemini Deep Research operated this way: first, a search plan was created, then the search was executed, and finally, the results were compiled.
Solutions operating in systems with a feedback loop. Various Claude Code, Cursor, and other code-generating agents fall into this group. The stronger the feedback loop—that is, the better the tooling and the stricter the type checking—the greater the chance they won’t completely wreck your codebase2.
Models trained using Reinforcement Learning, such as those with interleaved thinking, like OpenAI’s o3. This is a separate, very interesting conversation, but even these models have a certain modus operandi defined by the specifics of their training.
Meanwhile, open-ended multi-agent systems have largely remained in the proof-of-concept stage due to their general unreliability. The community lacked a clear understanding of where and how to implement them. This was the case until Anthropic published a deeply technical article on how they developed their Deep Research system. It defined a reasonably clear framework for building such systems, and that is what we will examine today.
The most important contribution of this article is the identification of a design pattern for multi-agent systems with dynamic orchestration. Yes, I’m drawing a direct analogy to the classic design patterns from the world of programming.
Classic patterns are densely packed nuggets of wisdom from architects and programmers who have built hundreds of thousands of software systems. By analyzing their work, they identified certain regularities, which they formalized to raise the level of abstraction for architectural problems and to facilitate communication.
The article calls it the “orchestrator-worker” pattern, which captures the essence but loses a key distinction from the classic pattern: the dynamic nature and adaptation of tasks for the workers based on the initial problem. I believe this is a significant enough feature to be reflected in the name. Other names they use—Advanced Research, multi-agent research system—are more about describing the application domain. Therefore, I will henceforth call it the “Adaptive Orchestrator,” or AdOrc4.
This unpredictability makes AI agents particularly well-suited for research tasks. Research demands the flexibility to pivot or explore tangential connections as the investigation unfolds. The model must operate autonomously for many turns, making decisions about which directions to pursue based on intermediate findings. A linear, one-shot pipeline cannot handle these tasks.
The essence of search is compression: distilling insights from a vast corpus. Subagents facilitate compression by operating in parallel with their own context windows, exploring different aspects of the question simultaneously before condensing the most important tokens for the lead research agent. Each subagent also provides separation of concerns—distinct tools, prompts, and exploration trajectories—which reduces path dependency and enables thorough, independent investigations.
…
Our internal evaluations show that multi-agent research systems excel especially for breadth-first queries that involve pursuing multiple independent directions simultaneously.
Here, the engineers clearly indicate where the pattern performs well:
In cases where the plan needs to be modified based on intermediate results. These are not deterministic business processes; they are explorations of the surrounding world. Search and research tasks fit perfectly here.
Where we hit the technical limitations of a single agent. The primary limitation is the context window, which brings along latency, high inference costs, and some quality degradation due to the nature of the attention mechanism.
Finally, in situations where a large number of independent, parallel subtasks can be launched. The pattern shines in tasks like patent searches or due diligence—areas where humans also work in parallel.
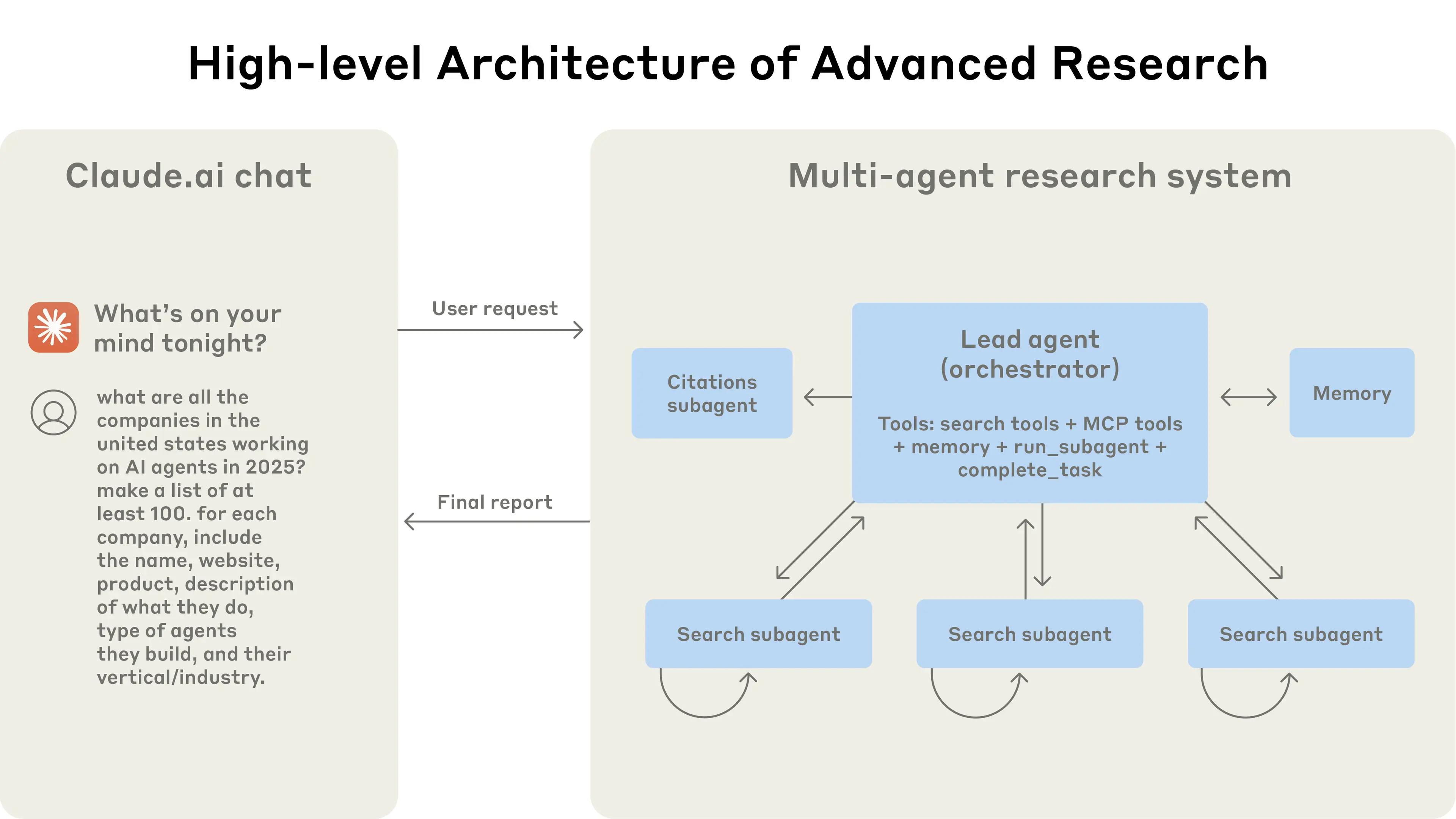
Our Research system uses a multi-agent architecture with an orchestrator-worker pattern, where a lead agent coordinates the process while delegating to specialized subagents that operate in parallel.
The multi-agent architecture in action: user queries flow through a lead agent that creates specialized subagents to search for different aspects in parallel (figure from the original post by Anthropic).
When a user submits a query, the lead agent analyzes it, develops a strategy, and spawns subagents to explore different aspects simultaneously. As shown in the diagram above, the subagents act as intelligent filters by iteratively using search tools to gather information, in this case on AI agent companies in 2025, and then returning a list of companies to the lead agent so it can compile a final answer.
Traditional approaches using Retrieval Augmented Generation (RAG) use static retrieval. That is, they fetch some set of chunks that are most similar to an input query and use these chunks to generate a response. In contrast, our architecture uses a multi-step search that dynamically finds relevant information, adapts to new findings, and analyzes results to formulate high-quality answers.
The structure of the pattern is clear from the description:
The system consists of an orchestrator and workers. These are LLMs (or LMMs5) with access to tools. The orchestrator can, in the general case, assign specific tools to specific workers.
The system receives a task and a description of the desired outcome.
The process begins by creating a plan where tasks can be executed by the orchestrator itself or by specialized workers, provided the conditions listed above are met.
At each step, the orchestrator launches the workers, which perform actions and return the resulting data.
At the end of the cycle, a completion condition is checked. The process either returns to step 3, where the orchestrator modifies the plan, or it terminates and returns the result to the user. Here are a few possible termination reasons:
The task requirements have been met (successful exit).
The allocated budget has been exceeded.
The specified number of iterations has been exceeded.
Convergence (no significant improvements over the last few iterations).
graph TD
subgraph "The AdOrc Cycle"
A("1\. Receive task and desired outcome") --> B("2\. Build / Modify plan");
B --> C("3\. Execute workers and get results");
C --> D{"4\. Check completion condition"};
D -- "No, refinement needed" --> B;
D -- "Yes, goal achieved" --> E("Return result to user");
end
subgraph "Termination Reasons"
F["-Result meets requirements<br/>-Budget or iteration limit exceeded<br/>-Convergence (no recent improvements)"];
end
D -.- F;
Now let’s look at where this pattern underperforms. The authors write:
… in practice, these architectures burn through tokens fast. In our data, agents typically use about 4× more tokens than chat interactions, and multi-agent systems use about 15× more tokens than chats. For economic viability, multi-agent systems require tasks where the value of the task is high enough to pay for the increased performance. Further, some domains that require all agents to share the same context or involve many dependencies between agents are not a good fit for multi-agent systems today. For instance, most coding tasks involve fewer truly parallelizable tasks than research, and LLM agents are not yet great at coordinating and delegating to other agents in real time.
…
Subagent output to a filesystem to minimize the ‘game of telephone.’ Direct subagent outputs can bypass the main coordinator for certain types of results, improving both fidelity and performance.
As we can see, this approach has its drawbacks:
Cost. Running such a system is expensive, so it should be used for tasks with relatively high economic value, such as analyzing case law, reviewing articles in a specific scientific field, or gathering feedback and advice when learning a new technology.
Agent independence. Yes, sometimes this is a disadvantage, for instance, when agents need to maintain a large shared context. An example would be a document processing system that analyzes a document from multiple perspectives simultaneously. In the Deep Research implementation, workers sometimes had to communicate via the filesystem, which should be seen as a workaround.
Latency. The cyclical nature of research using powerful (and therefore slow) models means that waiting several minutes for a result is normal. This requires a special approach to user interaction design, making it unsuitable for a vast range of applications.
Consequently, AdOrc is often not suitable for scenarios like:
Writing new code. As is well known, writing code doesn’t always play well with parallelism. Decomposing tasks so that team members don’t step on each other’s toes is a major headache. However, this pattern could be useful in other aspects of software development, such as onboarding to a new codebase, refactoring, and debugging.
Automating business processes. Most are relatively well-formalized and are better solved by agents with a fixed plan. Recently, case studies of larger, more flexible automations have appeared, but they don’t provide enough detail to assess their effectiveness and reliability.
Knowledge base search. While the pattern is applicable here in principle, its high latency and cost make classic RAG systems a better fit for such tasks.
Creating AGI or ASI. No, I’m not saying this pattern is inapplicable to AGI. It’s just that nobody knows what is applicable.
Now that we’ve covered what I consider the post’s main contribution to our technical field, let’s look at some of the advice Anthropic’s developers offer to builders of similar agentic systems. Since the developers accompanied their points with excellent notes, I won’t repeat them all, limiting myself to the ones that resonated most with me.
Start evaluating from the very beginning, even with a small sample. Model evaluation is expensive, complex, and confusing, which is why many products settle for “vibe checking,” or as it’s also known, “I tried this prompt in ChatGPT, and it seemed to work.” This path leads nowhere (or to multi-million dollar lawsuits, product failure, or a system jailbreak—underline as appropriate). Building an effective and automated eval and red teaming system to catch problems before they surface is a critical engineering practice. Not to mention that trying to improve system prompts without a reliable way to evaluate them is like hitting a piñata blindfolded.
For developing evals, you can use projects like promptfoo and DeepEval, which support many useful metrics and LLM-as-judge out of the box.
LLM-as-judge scales if you prepare it correctly. Yes, but its preparation is a special kind of art. Different LLMs evaluate the same output in completely different ways. The article suggests using an LLM to assign scores from 0 to 1. This directly contradicts well-known research showing that even powerful models cannot consistently assign such scores. The most reliable method of using LLM-as-judge is pairwise comparison of two results, often combined with majority voting and swapping the order of options. In short, something doesn’t quite add up with this piece of advice. However, it’s entirely possible that for the Deep Research implementation, these scores worked well enough.
Human evaluation catches what automation misses. Human evaluation is an expensive and highly subjective process. But you cannot skip this step, because it is the only way to identify corner cases not anticipated by your tests. The article gives an example of how a tester noticed that an early version of the system was being baited by SEO and was ignoring content-rich scientific papers and personal blogs. LLM-as-judge and other metrics couldn’t detect this on their own because they didn’t consider the resource type as an input parameter. After adding this parameter and certain heuristics to the prompt, the model’s behavior improved, and the tests were adapted to account for it.
Agents have state and accumulating error. Oh, this is the very problem that breaks multi-step agents without a feedback loop. It’s probability theory, and you can’t argue with it. If an agent has a 99% chance of completing a step correctly, what’s the probability of correctly completing a 10-step process? 90%. A 30-step process? 74%. A 100-step process will fail in 2/3 of cases. And this is an idealized situation. For a stochastic LLM operating in the messy real world, the probability of problems is significantly higher. We’re not just talking about predictable technical failures (a software defect, a weird encoding) but about issues specific to the model itself: hallucinations, logical leaps, context contamination, etc.
What makes it worse is that the consequences of errors persist in the agent’s state and “poison” all subsequent steps. The solution is either to introduce intermediate feedback, which isn’t always possible, or to limit the number of turns. It is the combination of these methods that allows the AdOrc pattern, and Deep Research in particular, to function properly. The number of turns for the orchestrator is small, but at each step, it launches multiple workers that are allowed to fail without seriously impacting the final result. At the same time, it receives information about all technical failures, providing it with a feedback loop to adapt and find workarounds.
Debugging benefits from new approaches. On this point, the post becomes disappointingly concise, even though this is precisely the information needed to build reliable agentic systems. Anthropic mentions logging decision-making patterns and interaction structures but doesn’t go into detail. However, it’s highly likely they have a fairly robust observability system in place:
All metadata (spans) about worker launches, the tools provided to them, the overall execution progress, and completion status are logged.
The interaction structures between the orchestrator and workers allow for the identification of decision-making patterns. For example, in 70% of cases, the system might restart a worker, while in 30% it might just continue with the plan.
Statistical processing of thousands of traces allows them to identify and strengthen the agent’s weak points without exposing the user data itself.
It would be fascinating to read a dedicated engineering article from them on this topic. Nevertheless, it’s quite clear that simple logging won’t cut it, and from the very beginning of such projects, systems like Langfuse or OpenTelemetry must be integrated.
I want to say a huge thank you to the Anthropic team for such a detailed and practical post. At a time when the implementation details of AI projects have become trade secrets guarded by seven seals, this feels like an artifact from another era, one that valued engineering ingenuity and elegant solutions, and where knowledge was a public good. Who knows, maybe we’ll return to that someday.
In the meantime, read the original post, subscribe to their engineering blog, and create. The rest will follow.