Zazwyczaj staram się podchodzić do wszelkich nowych, błyszczących zabawek z pewną dozą sceptycyzmu. Dokładnie taki, do niedawna, był mój stosunek do systemów wieloagentowych. Powiedziałbym, że nie jest to zaskakujące, ponieważ wokół nich jest teraz mnóstwo szumu, a ja nie widziałem prawdziwie udanych przykładów takiego podejścia. Większość realizacji, które faktycznie działały, należała do jednego z następujących typów:
- Systemy agentowe działające według określonego planu. Czyli LLM z narzędziami, wytrenowane do automatyzacji konkretnego procesu. Dzięki temu każdy krok można testować osobno i weryfikować jego wyniki. Opisywane są takie systemy zazwyczaj w postaci skierowanego grafu acyklicznego (DAG), czasem dynamicznego, i tworzone przy użyciu już standardowych prymitywów z frameworków typu LangChain i Griptape1. Tak funkcjonowała wczesna implementacja Gemini Deep Research, w której najpierw tworzono plan wyszukiwania, następnie wykonywano samo wyszukiwanie, a na końcu składano wynik.
- Rozwiązania działające w systemach ze sprzężeniem zwrotnym. Różne Claude Code, Cursor i inne agenty operujące na kodzie. Im silniejsze sprzężenie zwrotne, czyli im lepszy tooling i surowsza kontrola typów, tym większe szanse, że ostatecznie nie zepsują wam bazy kodu2.
- Modele trenowane za pomocą Reinforcement Learning, takie jak modele z interleaved thinking, na przykład OpenAI o3. To osobna i bardzo ciekawa rozmowa, ale nawet takie modele mają jakieś modus operandi, określone przez specyfikę ich treningu.
Tymczasem systemy wieloagentowe typu otwartego, ze względu na ich ogólną zawodność, istniały dotychczas głównie w formie proof of concept. W społeczności brakowało zrozumienia, gdzie je stosować i jak dokładnie je implementować. Aż pojawił się głęboki artykuł inżynierski od Anthropic o tym, jak tworzyli swój Deep Research. Zdefiniowano w nim wystarczająco jasne ramy do budowy takich systemów i to właśnie je dzisiaj przeanalizujemy.
Sedno sprawy
Najważniejsze w tym artykule jest wyodrębnienie wzorca systemów wieloagentowych z dynamiczną orkiestracją. Tak, tak, przeprowadzam tu bezpośrednią analogię do klasycznych wzorców projektowych ze świata programowania.
Klasyczne wzorce to gęsto upakowane fragmenty mądrości architektów i programistów, którzy napisali setki tysięcy systemów oprogramowania. Analizując je, wyodrębnili pewne prawidłowości, które sformalizowali w celu podniesienia poziomu abstrakcji problemów architektonicznych i ułatwienia komunikacji.
Dobry wzorzec składa się z3:
- Chwytliwej nazwy. Obowiązkowy składnik, bez którego wzorzec po prostu się nie przyjmie.
- Opisu problemu, który rozwiązuje. Zazwyczaj jest on na tyle ogólny, by warto było go uogólniać.
- Opisu samego wzorca.
- I opisu, gdzie nie należy go stosować.
Spójrzmy teraz na to, co inżynierowie Anthropic przedstawiają w swoim artykule:
Nazwa
W artykule nazywają go orkiestrator-worker, co oddaje istotę, ale gubi ważną różnicę w stosunku do klasycznego wzorca — dynamiczną naturę i adaptację zadań dla workerów w zależności od pierwotnego zadania. Uważam, że jest to na tyle istotna cecha, by odzwierciedlić ją w nazwie. Inne określenia, których używają — Advanced Research, multi-agent research system — dotyczą już raczej opisu obszaru zastosowań. Dlatego dalej będę go nazywał “Adaptive Orchestrator”, czyli AdOrc4.
Opis problemu
This unpredictability makes AI agents particularly well-suited for research tasks. Research demands the flexibility to pivot or explore tangential connections as the investigation unfolds. The model must operate autonomously for many turns, making decisions about which directions to pursue based on intermediate findings. A linear, one-shot pipeline cannot handle these tasks.
The essence of search is compression: distilling insights from a vast corpus. Subagents facilitate compression by operating in parallel with their own context windows, exploring different aspects of the question simultaneously before condensing the most important tokens for the lead research agent. Each subagent also provides separation of concerns—distinct tools, prompts, and exploration trajectories—which reduces path dependency and enables thorough, independent investigations.
…
Our internal evaluations show that multi-agent research systems excel especially for breadth-first queries that involve pursuing multiple independent directions simultaneously.
Inżynierowie jasno wskazują, w jakich przypadkach wzorzec sprawdza się dobrze:
- W przypadkach, gdzie konieczna jest modyfikacja planu w zależności od wyników pośrednich. To nie są deterministyczne procesy biznesowe, to badanie otaczającego świata. Zadania poszukiwawcze i badawcze idealnie tu pasują.
- Tam, gdzie napotykamy techniczne ograniczenia pojedynczego agenta. Głównym jest kontekst, ale pociąga on za sobą opóźnienia i wysoki koszt inferencji, a także pewien spadek jakości związany ze specyfiką mechanizmu uwagi.
- I wreszcie, w sytuacjach, w których istnieje możliwość uruchomienia dużej liczby niezależnych, równoległych podzadań. Wzorzec sprawdza się najlepiej np. w poszukiwaniach patentowych czy Due Diligence, czyli tam, gdzie ludzie również pracują równolegle.
Opis wzorca
Our Research system uses a multi-agent architecture with an orchestrator-worker pattern, where a lead agent coordinates the process while delegating to specialized subagents that operate in parallel.
The multi-agent architecture in action: user queries flow through a lead agent that creates specialized subagents to search for different aspects in parallel. 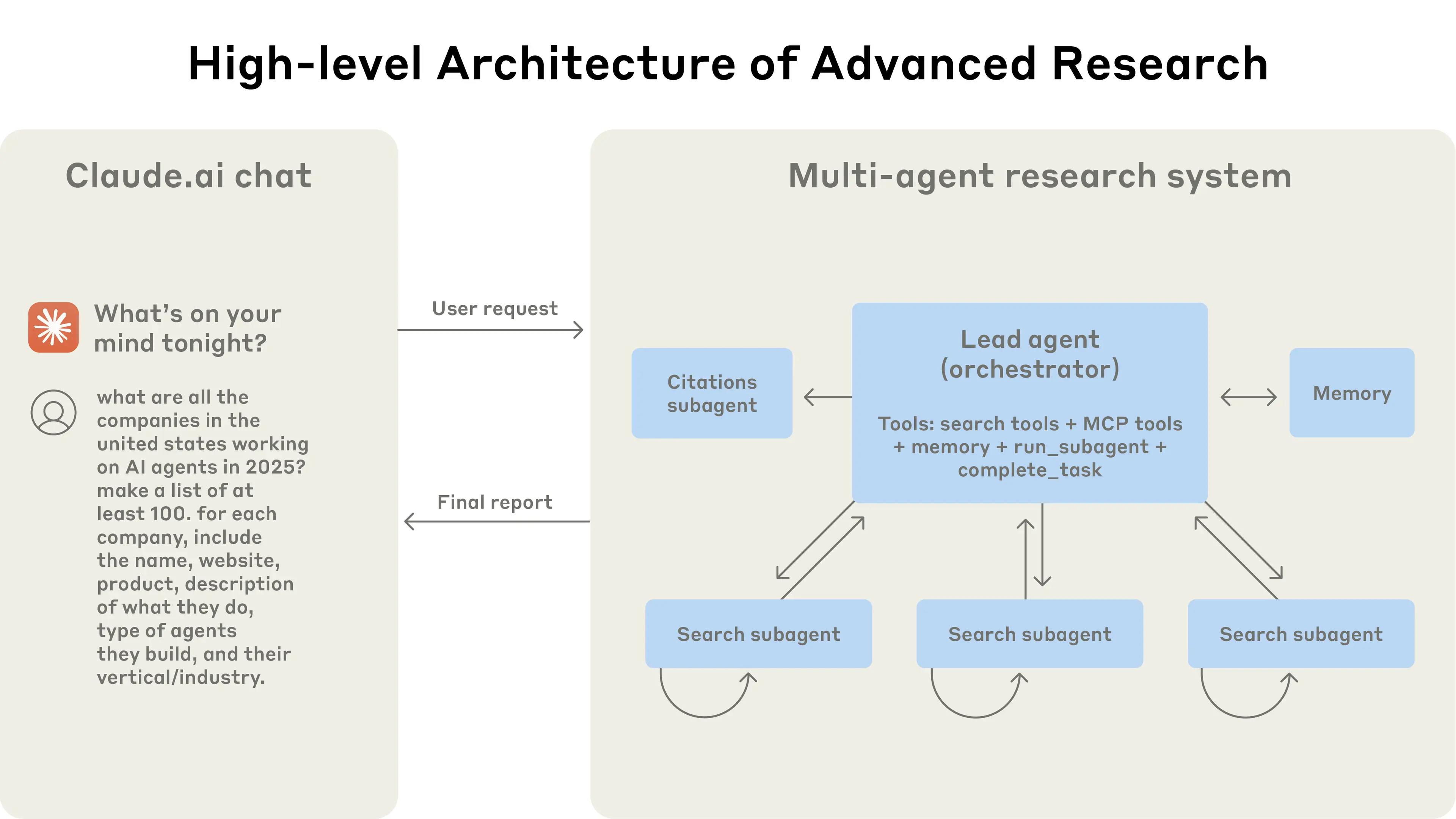
When a user submits a query, the lead agent analyzes it, develops a strategy, and spawns subagents to explore different aspects simultaneously. As shown in the diagram above, the subagents act as intelligent filters by iteratively using search tools to gather information, in this case on AI agent companies in 2025, and then returning a list of companies to the lead agent so it can compile a final answer.
Traditional approaches using Retrieval Augmented Generation (RAG) use static retrieval. That is, they fetch some set of chunks that are most similar to an input query and use these chunks to generate a response. In contrast, our architecture uses a multi-step search that dynamically finds relevant information, adapts to new findings, and analyzes results to formulate high-quality answers.
Struktura wzorca z opisu jest jasna:
- System składa się z orkiestratora i workerów. Są to LLM-y (lub LMM-y5) z dostępem do narzędzi. Orkiestrator w ogólnym przypadku może przydzielać konkretne narzędzia konkretnym workerom.
- Do systemu trafia zadanie oraz opis pożądanego rezultatu.
- Proces rozpoczyna się od budowy planu, w którym zadania mogą być wykonywane zarówno przez samego orkiestratora, jak i przez wyspecjalizowanych workerów, jeśli spełnia to warunki wymienione powyżej.
- Na każdym kroku orkiestrator uruchamia workerów, którzy wykonują działania i zwracają mu uzyskane dane.
- Na końcu cyklu sprawdzany jest warunek zakończenia, i proces albo wraca do punktu 3, gdzie orkiestrator modyfikuje plan, albo proces kończy się i wynik jest zwracany użytkownikowi. Podam kilka możliwych przyczyn zakończenia:
- Osiągnięcie wymagań zadania (pomyślne wyjście);
- Przekroczenie przydzielonego budżetu;
- Przekroczenie zadanej liczby iteracji;
- Zbieżność (brak widocznej poprawy w ostatnich kilku iteracjach).
graph TD
subgraph "Cykl AdOrc"
A("1\. Otrzymanie zadania i oczekiwanego rezultatu") --> B("2\. Budowa / Modyfikacja planu");
B --> C("3\. Uruchomienie workerów i odbiór wyników");
C --> D{"4\. Sprawdzenie warunku zakończenia"};
D -- "Nie, potrzebne dopracowanie" --> B;
D -- "Tak, cel osiągnięty" --> E("Zwrot wyniku do użytkownika");
end
subgraph "Powody zakończenia"
F["-Zgodność wyniku z wymaganiami<br/>-Przekroczenie budżetu lub limitu iteracji<br/>-Zbieżność wyniku (brak poprawy)"];
end
D -.- F;
Ograniczenia
Zobaczmy teraz, gdzie ten wzorzec sprawdza się gorzej. Autorzy piszą:
… in practice, these architectures burn through tokens fast. In our data, agents typically use about 4× more tokens than chat interactions, and multi-agent systems use about 15× more tokens than chats. For economic viability, multi-agent systems require tasks where the value of the task is high enough to pay for the increased performance. Further, some domains that require all agents to share the same context or involve many dependencies between agents are not a good fit for multi-agent systems today. For instance, most coding tasks involve fewer truly parallelizable tasks than research, and LLM agents are not yet great at coordinating and delegating to other agents in real time.
…
Subagent output to a filesystem to minimize the ‘game of telephone.’ Direct subagent outputs can bypass the main coordinator for certain types of results, improving both fidelity and performance.
Jak widać, podejście to ma również wady:
- Cena. Uruchomienie takiego systemu jest drogie, dlatego powinien być używany do zadań o stosunkowo wysokiej wartości ekonomicznej, np. analizy precedensów prawnych, przeglądu artykułów w określonej dziedzinie naukowej, zbierania opinii i porad przy nauce nowej technologii.
- Niezależność agentów. Tak, czasami jest to wada, na przykład, gdy agenci muszą utrzymywać duży wspólny kontekst. Przykładem może być system przetwarzania dokumentów, który jednocześnie analizuje dokument z różnych perspektyw. W implementacji Deep Research workerzy musieli czasami komunikować się przez system plików, co należy traktować jako protezę.
- Opóźnienia. Cykliczna natura badań z wykorzystaniem potężnych (a co za tym idzie, wolnych) modeli prowadzi do tego, że oczekiwanie na wynik przez kilka minut jest zjawiskiem normalnym. Wymaga to specjalnej konstrukcji interakcji z użytkownikiem, co czyni go nieodpowiednim dla ogromnej części zastosowań.
W związku z tym AdOrc najczęściej nie nadaje się do takich scenariuszy jak:
- Pisanie nowego kodu. Jak od dawna wiadomo, pisanie kodu nie zawsze idzie w parze z równoległością, a dzielenie zadań w taki sposób, aby członkowie zespołu sobie nie przeszkadzali, to poważny ból głowy. Niemniej jednak ten wzorzec może być przydatny w innych aspektach tworzenia oprogramowania, pomagając wejść w nową bazę kodu, refaktoryzować i debugować.
- Automatyzacja procesów biznesowych. Większość z nich jest stosunkowo dobrze sformalizowana i dlatego lepiej rozwiązują je agenci o stałym planie. Ostatnio pojawiają się studia przypadków bardziej rozbudowanych i elastycznych automatyzacji, ale nie dostarczają one wystarczającej ilości szczegółów, aby ocenić ich skuteczność i niezawodność.
- Przeszukiwanie baz wiedzy. Tutaj ten wzorzec jest w zasadzie stosowalny, ale ze względu na wysokie opóźnienia i koszty, do takich zadań lepiej nadają się klasyczne systemy RAG.
- Tworzenie AGI lub ASI. Nie, nie twierdzę, że ten wzorzec jest nieprzydatny do AGI. Po prostu nikt nie wie, co w ogóle jest do tego przydatne.
Pożyteczne rady
Teraz, gdy zapoznaliśmy się z moim zdaniem głównym wkładem tego posta w naszą wiedzę techniczną, spójrzmy na niektóre rady, których udzielają deweloperzy Anthropic budowniczym podobnych systemów agentowych. Ponieważ deweloperzy świetnie opatrzyli je swoimi notatkami, nie będę powtarzał ich wszystkich, ograniczę się tylko do tych, które najbardziej mi zaimponowały.
Zacznijcie oceniać od samego początku, nawet na małej próbce. Ewaluacja modelu jest droga, skomplikowana i niejasna, dlatego wiele produktów ogranicza się do “vibe checkingu”, lub, jak ta metoda jest jeszcze nazywana, “sprawdziłem ten prompt w ChatGPT, wydaje się, że działa”. Ta droga prowadzi donikąd (do wielomilionowych pozwów, do porażki produktu lub po prostu do jailbreaku systemu, niepotrzebne skreślić). Budowa skutecznego i automatycznego systemu ewaluacji i red teamingu, który pomoże wyłapywać problemy, zanim się jeszcze ujawnią, to ważna praktyka inżynierska. Nie wspominając o tym, że ulepszanie promptów systemu bez możliwości ich wiarygodnej oceny to coś z gatunku walenia w piniatę z zawiązanymi oczami.
Do tworzenia ewaluacji można używać takich projektów jak promptfoo i DeepEval, które wspierają wiele przydatnych metryk i LLM-as-judge “z pudełka”.
LLM-as-judge skaluje się, jeśli się go odpowiednio przygotuje. Tak, ale jego przygotowanie to sztuka sama w sobie. Różne LLM-y oceniają ten sam wynik zupełnie inaczej. W artykule proponuje się użycie LLM do wystawiania odpowiedziom ocen od 0 do 1. To bezpośrednio zaprzecza znanym pracom o tym, że nawet potężne modele nie potrafią konsekwentnie wystawiać podobnych ocen. Najbardziej niezawodną metodą użycia LLM-as-judge jest porównywanie parami dwóch wyników, i to z zastosowaniem głosowania większościowego oraz zamiany wariantów miejscami. Krótko mówiąc, w tej radzie coś się nie zgadza. Aczkolwiek, całkiem możliwe, że przy implementacji Deep Research oceny działały wystarczająco dobrze.
Ocena przez ludzi wyłapuje to, co przeoczyła automatyka. Ocena przez ludzi to drogi i skrajnie subiektywny proces. Ale tego kroku nie wolno pomijać, ponieważ tylko on może wykryć przypadki brzegowe, nieprzewidziane w testach. W artykule przytoczono przykład, jak tester zauważył, że początkowa wersja systemu dawała się nabrać na SEO i ignorowała bogate w treść artykuły naukowe i osobiste blogi. LLM-as-judge i inne metryki same w sobie nie mogły tego wykryć, ponieważ nie uwzględniały typu źródła jako parametru wejściowego. Po dodaniu tego parametru i pewnych heurystyk do promptu zachowanie modelu poprawiło się, a testy zostały dostosowane, aby uwzględniać ten parametr.
Agenci mają stan i kumulujący się błąd. Och, to jest właśnie ten problem, z powodu którego wieloetapowi agenci bez sprzężenia zwrotnego się psują. To teoria prawdopodobieństwa i nie da się z nią dyskutować. Jeśli agent ma 99% szans na poprawne ukończenie kroku, to jakie będzie prawdopodobieństwo poprawnego ukończenia 10-etapowego procesu? 90%. A trzydziestoetapowego? 74%. Stuetapowy proces będzie się psuł w 2/3 przypadków. A to jest sytuacja wyidealizowana. U stochastycznego LLM, działającego w chaotycznym realnym świecie, prawdopodobieństwo problemów jest znacznie wyższe. I nie chodzi tu tyle o przewidywalne awarie techniczne (wada programu, zła strona kodowa), co o specyficzne problemy samego modelu: halucynacje, skoki w logice, zaśmiecanie kontekstu itp.
Sytuację pogarsza fakt, że konsekwencje błędów pozostają w stanie agenta i “zatruwają” wszystkie kolejne kroki. Wyjściem jest albo wprowadzenie pośredniego sprzężenia zwrotnego, co nie zawsze jest możliwe, albo ograniczenie liczby kroków. To właśnie kombinacja tych metod pozwala wzorcowi AdOrc i w szczególności Deep Research normalnie funkcjonować. Liczba kroków orkiestratora jest tutaj mała, za to na każdym kroku uruchamia on wielu workerów, którzy mają prawo do błędu bez poważnego wpływu na końcowy wynik. Jednocześnie otrzymuje on informacje o wszystkich awariach technicznych, co dostarcza mu sprzężenia zwrotnego i pozwala adaptować się i szukać obejść.
Debugowanie zyskuje dzięki nowym podejściom. W tym punkcie post staje się aż nazbyt lakoniczny, chociaż to właśnie ta informacja jest niezbędna do budowy niezawodnych systemów agentowych. Anthropic wspomina o logowaniu wzorców podejmowania decyzji i struktur interakcji, ale nie wchodzi przy tym w szczegóły. Jednakże, najprawdopodobniej mają zbudowany dość poważny system do observability:
- Logowane są wszystkie metainformacje (spany) o uruchomieniu workerów, dostarczonych im narzędziach, ogólnym przebiegu wykonania i statusie zakończenia.
- Struktury interakcji orkiestratora i workerów pozwalają na definiowanie wzorców podejmowania decyzji. Na przykład w 70% przypadków system może zrestartować workera, a w 30% — po prostu kontynuować pracę zgodnie z planem.
- Statystyczna obróbka śladów (traces) tysięcy wywołań pozwala zidentyfikować i wzmocnić słabe punkty agenta, nie ujawniając samych danych użytkownika.
Ciekawie byłoby przeczytać ich artykuł inżynierski właśnie na ten temat. Niemniej jednak, jest całkiem jasne, że zwykłym logowaniem nie da się obejść i od samego początku projektów tej klasy trzeba закладывать systemy takie jak Langfuse czy OpenTelemetry.
Podsumowując
Powiem wprost — chciałbym serdecznie podziękować zespołowi Anthropic za tak szczegółowy i praktyczny post. W czasach, gdy szczegóły implementacji projektów AI stały się tajemnicą handlową, strzeżoną za siedmioma pieczęciami, wygląda on jak artefakt z innej epoki, kiedy ceniono inżynierską pomysłowość i eleganckie rozwiązania, a wiedza była dobrem publicznym. Kto wie, może jeszcze tam wrócimy.
A tymczasem — czytajcie oryginalny post, subskrybujcie ich blog inżynierski i twórzcie. A wszystko będzie.
Którego przegląd można przeczytać w części pierwszej i drugiej. ↩︎
Czasem przychodzi mi do głowy myśl, że przyszłość programowania należy do Haskella, z jego paradygmatem “Jeśli program się skompilował — to prawdopodobnie działa”. ↩︎
Tutaj nie będę zbytnio formalizował i sprowadzał do struktury podobnej do tej opisanej w książce “Gang of Four”. ↩︎
Czyta się jak “a dork”, co nie ma absolutnie żadnego związku z charakterem orkiestratora. ↩︎
Odpowiednio Large Language Models i Large Multimodal Models. ↩︎