Обычно я стараюсь подходить ко всяким новым блестящим штучкам с определенной долей скептицизма. Именно таким, до недавнего времени, было мое отношение к мультиагентным системам. Я бы сказал, что это неудивительно, так как вокруг них сейчас очень много шума, а по-настоящему успешных примеров такого подхода я не видел. Большинство реализаций, которые действительно работали, относились к одному из следующих видов:
- Агентные системы, действующие по определенному плану. То есть LLM с инструментами, натасканные на автоматизацию вполне конкретного процесса. Благодаря этому, каждый шаг можно тестировать по отдельности и верифицировать его результаты. Описываются такие системы, как правило, в виде направленного ациклического графа (DAG), иногда динамического, и разрабатываются с помощью уже стандартных примитивов из фреймворков типа LangChain и Griptape1. Так функционировала ранняя реализация Gemini Deep Research, в которой сначала составлялся план поиска, затем выполнялся сам поиск, и в конце собирался результат.
- Решения, работающие в системах с обратной связью. Различные Claude Code, Cursor и прочие агенты, имеющие дело с кодом. Причем чем сильнее обратная связь, читай, чем лучше тулинг и строже проверка типов, тем больше шансов, что они окончательно не испортят вам кодовую базу2.
- Модели, обученные с помощью Reinforcement Learning, такие как модели с interleaved thinking, вроде OpenAI o3. Это отдельный разговор, и очень интересный, но даже такие модели имеют какой-то modus operandi, определенный особенностями их обучения.
При этом мультиагентные системы открытого типа ввиду их общей ненадежности до сих пор существовали в большей части в виде proof of concept. В сообществе не было понимания, где их применять и как именно их реализовывать. Пока не появилась глубокая инженерная статья от Anthropic о том, как они разрабатывали свой Deep Research. В ней был определен достаточно четкий фреймворк для построения таких систем, и именно его мы сегодня и рассмотрим.
Самое главное
Самое главное в этой статье — это выделение паттерна мультиагентных систем с динамической оркестрацией. Да-да, я провожу здесь прямую аналогию с классическими паттернами проектирования из мира программирования.
Классические паттерны — это плотно упакованные кусочки мудрости архитекторов и программистов, написавших сотни тысяч программных систем. Проанализировав их, они выделили определенные закономерности, которые формализовали для повышения уровня абстракции архитектурных проблем и удобства коммуникации.
Хороший паттерн состоит из3:
- Цепкого названия. Обязательный компонент, без которого паттерн попросту не приживется.
- Описания задачи, которую он решает. Как правило, она достаточно общая, чтобы ее имело смысл обобщать.
- Описания самого паттерна.
- И описания того, где его применять не следует.
Посмотрим теперь на то, что инженеры Anthropic приводят в своей статье:
Название
В статье его называют orchestrator-worker, что отражает суть, но теряет важное отличие от классического паттерна — динамическую природу и адаптацию заданий для рабочих в зависимости от изначальной задачи. Я считаю, что это достаточно серьезная особенность, чтобы отразить ее в названии. Другие наименования, которые они используют — Advanced Research, multi-agent research system — это уже скорее про описание области применения. Поэтому дальше я буду называть его “Adaptive Orchestrator”, или AdOrc4.
Описание задачи
This unpredictability makes AI agents particularly well-suited for research tasks. Research demands the flexibility to pivot or explore tangential connections as the investigation unfolds. The model must operate autonomously for many turns, making decisions about which directions to pursue based on intermediate findings. A linear, one-shot pipeline cannot handle these tasks.
The essence of search is compression: distilling insights from a vast corpus. Subagents facilitate compression by operating in parallel with their own context windows, exploring different aspects of the question simultaneously before condensing the most important tokens for the lead research agent. Each subagent also provides separation of concerns—distinct tools, prompts, and exploration trajectories—which reduces path dependency and enables thorough, independent investigations.
…
Our internal evaluations show that multi-agent research systems excel especially for breadth-first queries that involve pursuing multiple independent directions simultaneously.
Здесь инженеры четко указывают, в каких случаях паттерн хорошо себя показывает:
- В случаях, где необходимо модифицировать план в зависимости от промежуточных результатов. Это не детерминированные бизнес-процессы, это исследование окружающего мира. Поисковые и исследовательские задачи ложатся сюда идеально.
- Там мы упираемся в технические ограничения одного агента. Основным является контекст, но он тянет за собой задержки и высокую стоимость инференса, а также некоторое падение качества, связанное с особенностями механизма внимания.
- И наконец, в ситуациях, в которых есть возможность запуска большого количества независимых параллельных подзадач. Паттерн показывает себя в лучшем виде, например, в патентных поисках или Due Diligence, то есть там, где люди тоже работают параллельно.
Описание паттерна
Our Research system uses a multi-agent architecture with an orchestrator-worker pattern, where a lead agent coordinates the process while delegating to specialized subagents that operate in parallel.
The multi-agent architecture in action: user queries flow through a lead agent that creates specialized subagents to search for different aspects in parallel. 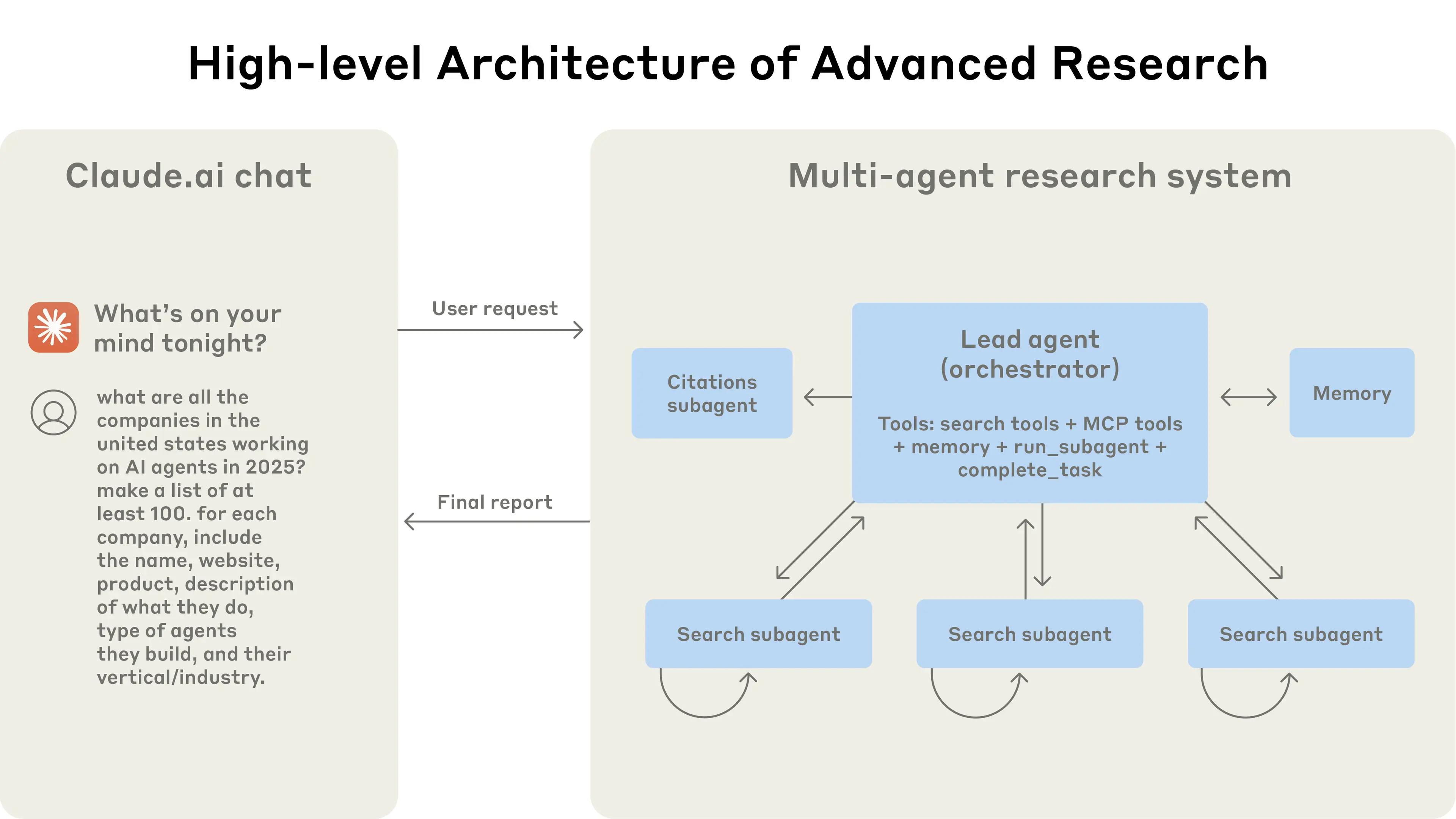
When a user submits a query, the lead agent analyzes it, develops a strategy, and spawns subagents to explore different aspects simultaneously. As shown in the diagram above, the subagents act as intelligent filters by iteratively using search tools to gather information, in this case on AI agent companies in 2025, and then returning a list of companies to the lead agent so it can compile a final answer.
Traditional approaches using Retrieval Augmented Generation (RAG) use static retrieval. That is, they fetch some set of chunks that are most similar to an input query and use these chunks to generate a response. In contrast, our architecture uses a multi-step search that dynamically finds relevant information, adapts to new findings, and analyzes results to formulate high-quality answers.
Итак, структура паттерна из описания ясна:
- Система состоит из оркестратора и рабочих. Они — это LLM (или LMM5) с доступом к инструментам. Оркестратор в общем случае может выделять конкретные инструменты конкретным рабочим.
- В систему поступают задание и что описание желаемого результата.
- Процесс начинается с построения плана, в котором задачи могут выполняться как самим оркестратором, так и специализированными рабочими, в случае, когда это удовлетворяет условиям, перечисленным выше.
- На каждом шаге оркестратор запускает рабочих, которые выполняют действия и возвращают ему полученные данные.
- В конце цикла проверяется условие завершения, и процесс либо возвращается к пункту 3, где оркестратор модифицирует план, либо процесс завершается и результат возвращается пользователю. Приведу несколько возможных причин завершения:
- Достижение требований задачи (успешный выход);
- Превышение выделенного бюджета;
- Превышение заданного количества итераций;
- Схождение (отсутствие видимых улучшений за последние несколько итераций).
graph TD
subgraph "Цикл AdOrc"
A(1\. Получение задания и желаемого результата) --> B(2\. Построение / Модификация плана);
B --> C(3\. Запуск рабочих и получение результатов);
C --> D{4\. Проверка условия завершения};
D -- Нет, нужна доработка --> B;
D -- Да, цель достигнута --> E(Возврат результата пользователю);
end
subgraph "Причины завершения"
F["-Соответствие результата требованиям<br/>-Превышение бюджета или лимита итераций<br/>-Схождение результата (отсутствие улучшений)"];
end
D -.- F;
Ограничения
Посмотрим теперь, где этот паттерн показывает себя хуже. Авторы пишут следующее:
… in practice, these architectures burn through tokens fast. In our data, agents typically use about 4× more tokens than chat interactions, and multi-agent systems use about 15× more tokens than chats. For economic viability, multi-agent systems require tasks where the value of the task is high enough to pay for the increased performance. Further, some domains that require all agents to share the same context or involve many dependencies between agents are not a good fit for multi-agent systems today. For instance, most coding tasks involve fewer truly parallelizable tasks than research, and LLM agents are not yet great at coordinating and delegating to other agents in real time.
…
Subagent output to a filesystem to minimize the ‘game of telephone.’ Direct subagent outputs can bypass the main coordinator for certain types of results, improving both fidelity and performance.
Как мы видим, недостатки у такого подхода тоже есть:
- Цена. Запуск такой системы дорог, поэтому он должен использоваться для задач с относительно высокой экономической ценностью, например, анализ прецедентного права, обзор статей в определенной научной области, сбор отзывов и советов при изучении новой технологии.
- Независимость агентов. Да, иногда это недостаток, к примеру, когда агентам нужно держать большой общий контекст. Примером может служить система обработки документов, одновременно анализирующая документ с разных точек зрения. В реализации Deep Research рабочим приходилось иногда коммуницировать через файловую систему, что стоит рассматривать как костыль.
- Задержки. Циклическая природа исследования с использованием мощных (и, соответственно, медленных) моделей, приводит к тому, что ожидание результата в течение нескольких минут — нормальное явление. Это требует особого построения взаимодействия с пользователем, что делает его неприменимым для огромного пласта приложений.
Соответственно, AdOrc чаще всего не подходит для таких сценариев, как:
- Написание нового кода. Как уже давно известно, написание кода не всегда дружит с параллелизмом, и разбиение заданий таким образом, чтобы члены команды не мешали друг другу — это серьезная головная боль. Тем не менее этот шаблон может быть полезен в других аспектах разработки ПО, помогая погружаться в новую кодовую базу, рефакторить и отлаживать.
- Автоматизация бизнес-процессов. Большинство из них относительно хорошо формализованы, и поэтому лучше решаются агентами с фиксированным планом. В последнее время появляются кейс-стади более масштабных и гибких автоматизаций, но они не предоставляют достаточного количества деталей, чтобы оценить их эффективность и надежность.
- Поиск по базам знаний. Здесь данный паттерн в принципе применим, но ввиду его высоких задержек и стоимости, для таких задач классические RAG-системы подходят лучше.
- Создание AGI или ASI. Нет, я не говорю, что этот паттерн неприменим для AGI. Просто никто не знает, что для этого вообще применимо.
Невредные советы
Теперь, когда мы познакомились с главным по моему мнению вкладом поста в наше техническое поле знаний, посмотрим на некоторые советы, которые дают разработчики Anthropic строителям подобных агентных систем. Поскольку разработчики отлично сопроводили их своими заметками, я не буду повторять их все, ограничусь только наиболее мне импонирующими.
Начинайте оценивать с самого начала, даже с маленькой выборкой. Оценка модели — это дорого, сложно и непонятно, и поэтому многие продукты ограничиваются “vibe checking”, или, как этот метод еще называют “я попробовал этот промпт в ChatGPT, вроде работает”. Этот путь ведет в никуда (к многомиллионным искам, к провалу продукта, или просто к джейлбрейку системы, нужное подчеркнуть). Построение эффективной и автоматической eval и red teaming системы, которая поможет отлавливать проблемы, пока они еще не проявились — это важная инженерная практика. И это не говоря о том, что улучшение промптов системы без возможности их надежно оценить — это что-то из разряда избиения пиньяты с завязанными глазами. Для разработки eval можно использовать такие проекты, как promptfoo и DeepEval, которые поддерживают множество полезных метрик и LLM-as-judge из коробки.
LLM-as-judge масштабируется, если приготовить его правильно. Да, но его готовка — особое искусство. Различные LLM оценивают один и тот же вывод совершенно по-разному. В статье предлагается использовать LLM для выставления ответам оценок от 0 до 1. Это прямо противоречит известным работам о том, что даже мощные модели не могут последовательно выставлять подобные оценки. Наиболее надежный метод использования LLM-as-judge — это попарное сравнение двух результатов, да еще и с применением мажоритарного голосования и перестановки вариантов местами. В общем, в данном совете что-то не сходится. Впрочем, вполне возможно, что при реализации Deep Research оценки работали достаточно хорошо.
Оценка людьми ловит то, что пропустила автоматика. Оценка людьми — дорогой и крайне субъективный процесс. Но выбрасывать этот шаг из процесса нельзя, потому что только он может выявить корнер-кейсы, не предусмотренные тестами. В статье приводятся пример того, как тестировщик увидел, что начальная версия системы велась на SEO и игнорировала богатые полезным контентом научные статьи и персональные блоги. LLM-as-judge и другие метрики сами по себе этого обнаружить не могли, поскольку не учитывали тип ресурса как входной параметр. После добавления этого параметра и определенных эвристик к промпту поведение модели улучшилось, и тесты были адаптированы, чтобы учитывать этот параметр.
Агенты обладают состоянием и накапливающейся ошибкой. Охохо, это та самая проблема, из-за которой многошаговые агенты без обратной связи ломаются. Это теория вероятности, и с ней не поспоришь. Если у агента есть 99% вероятность завершить шаг верно, то какая вероятность будет корректно завершить 10-шаговый процесс? 90%. А тридцатишаговый? 74%. Стошаговый процесс будет ломаться в 2/3 случаев. И это идеализированная ситуация. У стохастической LLM, работающей в беспорядочном реальном мире, вероятность проблем значительно выше. И речь не столько о предсказуемых технических сбоях (дефект программы, кривая кодировка), сколько о специфических проблемах самой модели: галлюцинациях, скачках в логике, засорении контекста и т.д.
Усугубляет ситуацию то, что последствия ошибок сохраняются в состоянии агента и “отравляет” все последующие шаги. Выход здесь — это либо вводить промежуточную обратную связь, что не всегда возможно, либо ограничивать количество ходов. Именно комбинация этих способов позволяет шаблону AdOrc и Deep Research в частности нормально работать. Количество ходов оркестратора здесь малО, зато на каждом шаге он запускает множество рабочих, которые имеют право на ошибку без серьезного влияния на конечный результат. При этом он получает информацию обо всех технических сбоях, что предоставляет ему обратную связь и позволяет адаптироваться и искать обходные пути.
Дебаггинг выигрывает от новых подходов. В этом пункте пост становится до обидного лаконичным, хотя именно эта информация необходима для построения надежных агентных систем. Anthropic упоминают логирование шаблонов принятия решений и структур взаимодействия, но не вдаются при этом в детали. Однако, вероятнее всего у них выстроена довольно серьезная система для observability:
- Логируется вся метаинформация (spans) о запуске рабочих, инструментов, им предоставленных, общем ходе выполнения и статусе завершения.
- Структуры взаимодействия оркестратора и рабочих позволяют определять шаблоны принятия решений. К примеру, в 70% случаев система может перезапустить рабочего, а в 30% — просто продолжить работу по плану.
- Статистическая обработка трейсов тысяч вызовов позволяет определить и усилить слабые точки агента, не раскрывая самих пользовательских данных.
Было бы интересно прочитать их инженерную статью именно по этой теме. Тем не менее вполне ясно, что обычным логированием не обойтись, и с самого начала проектов такого класса нужно закладывать системы вроде Langfuse или OpenTelemetry.
Подводя итоги
Скажу прямо — хочется сказать огромное спасибо команде Anthropic за такой подробный и практический пост. В то время, когда детали реализации AI проектов стали коммерческой тайной, хранимой за семью печатями, он выглядит как артефакт из иной эпохи, когда ценились инженерская смекалка и элегантные решения, а знания были достоянием общественности. Кто знает, возможно мы туда еще вернемся.
А между тем — читайте оригинальный пост, подписывайтесь на их инженерный блог, и творите. И все будет.
Мне порой приходит в голову мысль, что будущее программирования за Haskell, с его парадигмой “Если программа скомпилировалась — она, скорее всего, работает”. ↩︎
Здесь я не буду слишком формализировать и приводить к структуре, подобной той, что описана в книге Gang of Four. ↩︎
Читается как “a dork”, что абсолютно никак не связано с характером оркестратора. ↩︎
Large Language Models и Large Multimodal Models соответственно. ↩︎